本文共 1200 字,大约阅读时间需要 4 分钟。

1.概述
转载:
一、一个iTerm2蛋疼的问题
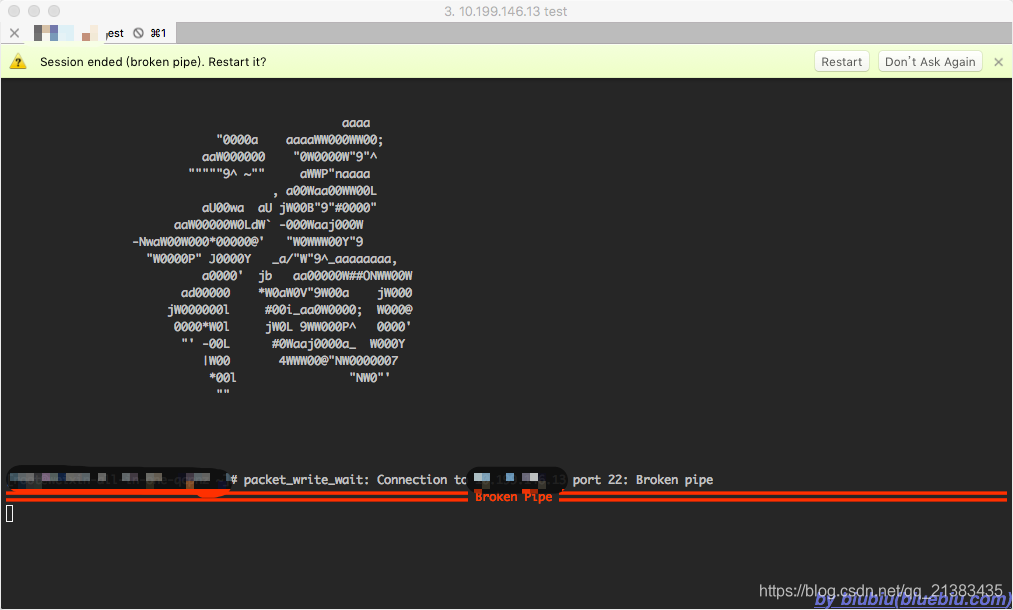
最近基友搞了台mbp,在装一些常用app时,跟我交流到一个情况:「用iTerm2进行ssh时,空闲了一段时间就会断掉了……」想来,这个情形也是之前总遇到的,尤其正开着vim开开心心的一把梭时,突然有产品汪跑来跟你沟通需求细节,等好不容易聊完,人家的需求有了,你TM代码呢?……于是又吭哧吭哧回到刚才的界面,正准备撸起袖子加油干,却发现冰冷的窗口上一点反应都没有了……
二、解决?解决!
看这情况,是服务器端把空闲连接给断开了。只能重新连接了。这么蛋疼,是该找点法子处理下了。
随手一搜,锦囊到手。
1、方案一(通过iTerm2参数配置)
刚接触iTerm2,用起来感觉还不错,就是不知道如何保持连接,让ssh不断线。 profiles -> sessions -> When idel, send ASCII code [1]
(我就不说这回答把「idle」都拼错了……-0-)
很快,按照设置,配好,验证,好了。

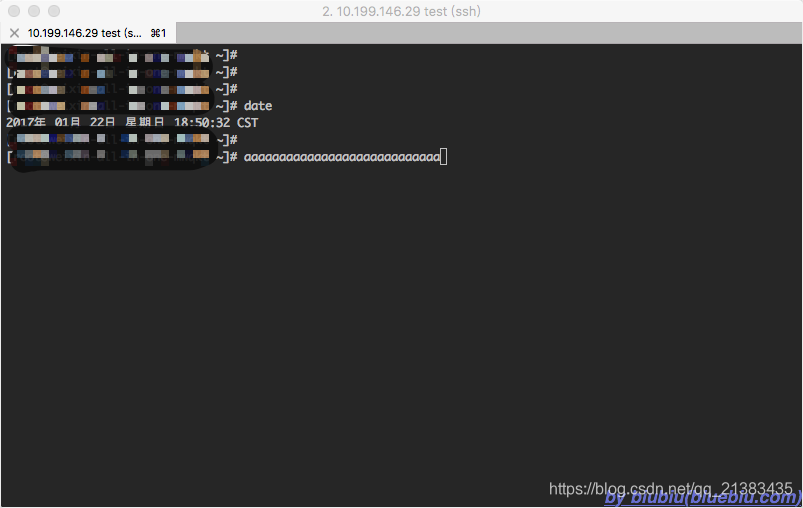
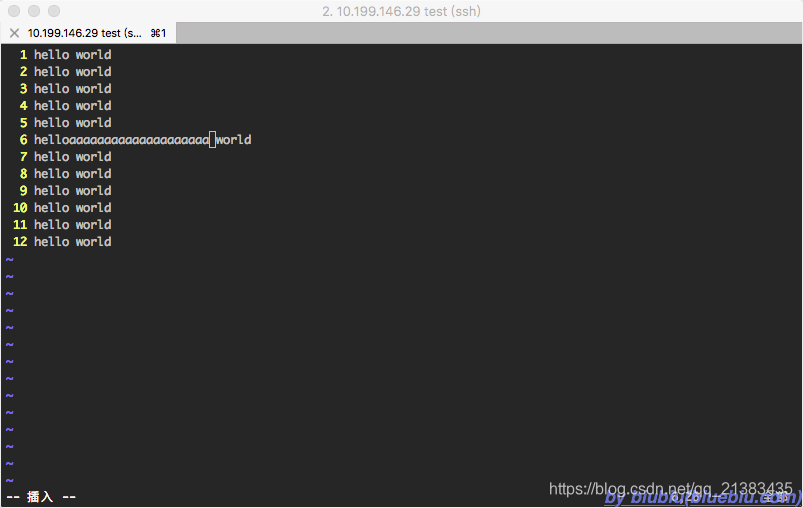 开着vim,过了一段时间再回来时,这一长串aaaaaa……还要手工ESC,u一下,才恢复,而且指不定还会有其它副作用,实在蛋疼……
开着vim,过了一段时间再回来时,这一长串aaaaaa……还要手工ESC,u一下,才恢复,而且指不定还会有其它副作用,实在蛋疼…… 2、方案二(通过客户端ssh参数配置)
正确的做法是,通过配置 ServerAliveInterval 来实现,在 ~/.ssh/config 中加入: ServerAliveInterval=30[2]
ServerAliveInterval 30 #表示ssh客户端每隔30秒给远程主机发送一个no-op包,no-op是无任何操作的意思,这样远程主机就不会关闭这个SSH会话。[3]
好的,二话不说,马上改!

我只需要在当前用户的ssh连接调整就好(注意:是本地发起连接的客户端!并非修改所要连接的远程服务器端),那么vim ~/.ssh/config,然后新增
Host * ServerAliveInterval 60
我觉得60秒就好了,而且基本去连的机器都保持,所以配置了*,如果有需要针对某个机器,可以自行配置为需要的serverHostName。
再经过最后的验证,方案二确实为最优选择。
三、补充
1、单次连接
若只是单次连接时需要,可使用-o参数实现: ssh -o ServerAliveInterval=30 user@host
2、罪魁祸首?
最后看下服务端的配置:

好吧,这个问题记下了,留着下次研究。 (果然发现,之前把问题想得太简单了,后面原来隐藏了这么个秘密……「」)